이번 글에서는 문자열의 기본적인 정렬 방법을 알아본 후 데이터를 정렬하여 화면에 표시해 주는 유티리티 프로그램을 만들어 보겠다.
문자열에는 ljust, rjust, center라는 세가지 메서드가 있는데 각각 특정 길이에 맞춰 대상 문자열이 왼쪽(ljust), 오른쪽(rjust), 중앙(center)에 오도록 변경된 새 문자열을 반환해 준다.
아래 그림처럼 테스트를 직접 해 보면 각각의 메서드의 동작 방식을 쉽게 이해할 수 있을 것이다.

이제 정렬 표시 유티리티 프로그램을 만들 기본 준비가 되었으니 바로 시작해 보자.
이전 글의 주식 조회 프로그램에서 내 주식 종목을 조회할 때 아래와 같이 헤더와 값들이 정렬되지 않고 출력됐었다.

프로그램을 간단히 하기 위해 배열을 사용하여 헤더와 주식 정보 데이터를 구성하고 배열의 내용을 화면에 정렬해서 출력해 보자.
정렬을 위해서는 어떤 헤더(예: 종목명)와 그 헤더에 해당하는 값들(예: 삼성전자, 현대차)이 모두 특정 너비에 맞춰 정렬이 되어야 하는데 그러기 위해서는 먼저 헤더를 포함한 모든 값들 중에서 (문자열로 표현했을 때의) 최대 너비를 구해야 한다.
즉 같은 열의 값 "abc" 와 "abcde" 를 정렬해서 표현하려면 해당 열의 너비는 최소 5는 되어야 한다는 얘기다.
그런데 최대 너비를 구하기 위해 문자열의 size나 length 메서드를 사용한다면 '한글'의 경우에는 단순히 글자수가 반환되어 실제 화면에 보여지는 글자 너비와는 달라 최대 너비를 올바르게 구할 수 없다.
아래 그림을 보면 "종목명" 과 "abc" 모두 length 메서드의 결과가 3이 되고 "123456" 은 6이 되는데 마지막 화면 출력 결과를 보면 "종목명" 과 "123456" 이 화면에 출력된 너비가 같아 보임을 알 수 있다.

그렇다면 '종목명' 이라는 문자열의 너비를 구할 때 6이 나오면 되는데 우선 bytesize 메서드를 시도해 보자. 결과를 보면 9가 나옴을 알 수 있다. 문자열의 현재 인코딩을 보면 UTF-8 인데 이것을 CP949로 변경한 후 다시 bytesize 메서드를 호출해 보자. 우리가 원하는 6이 나오는 걸 볼 수 있다.

컴퓨터 상의 모든 데이터는 바이트를 기본 단위로 하여 처리 및 저장을 하는데 우리가 작성한 소스 코드를 파일을 통해 하드 디스크 등에 저장을 하거나 네트워크를 통해 전송을 할 때에도 바이트로 변환되어 저장 및 전송이 된다.
이때 각각의 문자들을 특정 바이트로 변환하는 작업, 즉 인코딩이 필요한데 UTF-8은 전 세계 모든 문자를 표현할 수 있는 범용적인 문자 인코딩 방식이고 CP949는 한국어 문자 전용 인코딩 방식이다.
아래 그림을 보면 한글 한 문자 '종'에 대해 bytes 메서드를 호출하면 10진수로 나타낸 바이트 세 개가 들어 있는 배열을 볼 수 있는데 이것이 한글 '종'을 UTF-8로 인코딩 했을 때의 바이트 열이 된다.
그리고 인코딩 방식을 UTF-8에서 CP949로 변환한 후 다시 bytes 메서드를 호출하면 이때는 바이트 두 개가 들어 있는 배열이 나온다.

즉, UTF-8에서는 한글 문자 하나를 바이트 3개로 인코딩하지만 CP949는 바이트 2개로 인코딩하는 걸 알 수 있다.
CP949가 한글 문자 전용 인코딩 방식이므로 더 적은 바이트 수를 사용해서 표현이 가능한 것 같다.
알파벳이나 숫자(문자)의 경우에는 인코딩 방식과 상관없이 각 문자가 1 바이트로 인코딩됨을 알 수 있다.
어쨌든 우리는 정렬하고자 하는 값이 문자열일 경우에는 인코딩 방식을 CP949로 변환한 후에 bytesize 메서드를 통해 구한 값이 해당 문자열의 너비라고 생각하면 될 것 같다.
아래 코드를 보면 변수 data에 헤더와 데이터를 2차원 배열 형태로 만들어 할당했다.
제일 먼저 문자열 데이터는 CP949로 인코딩 변환을 하고 문자열이 아닌 경우에는 문자열로 변환하는 처리가 필요하다.
이때 배열 내 요소들에 대한 변환 처리 등에 적합한 map 메서드를 사용하였는데 2차원 배열이므로 첫 번째 map 메서드의 블록 안에서 다시 map 메서드를 호출하였다.
그 다음 각 열에 대한 최대 너비를 구해야 하는데 2차원 배열에서 각 열은 내부 배열(행)들에서 같은 인덱스를 갖는 요소들이 된다. 즉 data[0][0], data[1][0], data[2][0] 이 같은 열이라고 할 수 있다.
배열의 transpose 메서드를 사용하면 2차원 배열에서 같은 열끼리 모아 새롭게 구성한 2차원 배열을 만들어 준다.
즉 [[1,2,3], [4,5,6], [7,8,9]] 배열에 대해 transpose 메서드를 호출하면 결괏값은 [[1,4,7], [2,5,8], [3,6,9]] 배열이 된다.
아래 실행 결과 그림에서도 'p data.transpose' 의 출력 내용을 확인해 보길 바란다.
transpose 메서드를 통해 같은 열의 데이터(문자열)끼리 한 배열에 모아 놓았으니 이제 그 배열에 담긴 문자열들의 너비 중에서 최대값을 찾으면 된다. 이때도 map 메서드를 사용하면 편하다.
안쪽의 map 메서드는 각 배열 요소의 bytesize 값이 결괏값이 되도록 블록을 작성하고 바깥쪽의 map 메서드는 안쪽 map 메서드 호출의 결괏값인 너비를 담은 배열의 max 값이 결괏값이 되도록 블록을 작성하면 된다.
그러면 col_widths 변수는 최종적으로 각 열에 대한 최대 너비값이 담긴 배열을 받게된다.
data = [["종목명", "구매단가", "현재가"],
["삼성전자", "77,500", "74,300"],
["현대차", "245,000", "246,000"]]
p data.transpose
data = data.map do |row|
row.map do |col|
if col.is_a?(String)
col.encode("CP949")
else
col.to_s
end
end
end
col_widths = data.transpose.map { |cols| cols.map { |col| col.bytesize }.max }
p col_widths
puts
data.each do |row|
row.each_with_index do |col, i|
print col.ljust(col_widths[i] + (col.size - col.bytesize) + 2)
end
puts
end이제 정렬을 위해 기준이 될 너비값을 구했으니 이 값을 사용해서 정렬을 하면 되는데 한 가지 신경써야 할 게 남았다.
지금 irb 창을 열어 "종목명".ljust(6, "*") 을 실행해 보라. 종목명 뒤에 '*' 가 세 개가 나오는데 아마도 ljust 메서드 안에서 대상 문자열('종목명')의 size 메서드 결과(3)와 인수 6 을 비교하는 것 같다.
이렇게 되면 너비를 6에 맞추고 싶었지만 실제 9가 되어 또 정렬이 틀어지게 되므로 ljust 에 우리가 구한 최대 너비값을 그대로 전달하지 말고 보정값을 더해 값을 보정해 줘야 한다.
이때 조정 값은 출력 대상 문자열의 size 값에서 bytesize 값을 뺀 값이 된다. "종목명".ljust(6, "*") 의 코드에 대해 너비 보정값을 구하면 3(size) - 6(bytesize)으로 -3 이 되고 이 보정값을 너비 6 에 더해주면 3 이 된다.
즉 "종목명".ljust(6 + (3 - 6), "*") 의 결괏값은 '*' 없이 "종목명" 이 되어 내가 원하는 대로 화면 출력상 너비 6이 된다.

그리고 바로 옆의 데이터와 딱 붙어서 출력되지 않도록 여백을 주기 위해 2를 더해 주었다.
이제 해당 코드를 test_just.rb 파일에 저장한 후 테스트 해보자.
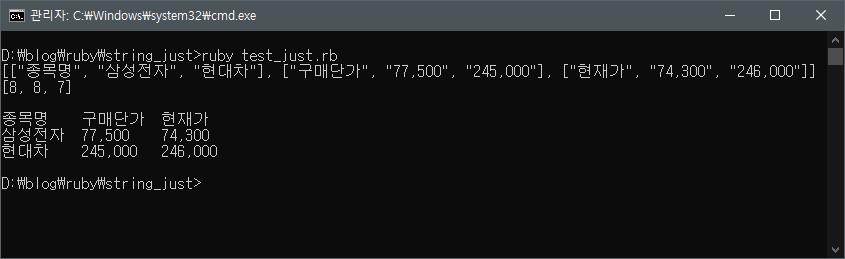
다음 글에서는 아래 그림처럼 행 번호 추가와 테이블 형태로 출력되도록 프로그램을 조금 더 업그레이드 시켜보겠다.

See you again~~