오늘은 지난번 글에 이어서 실제로 배열을 당첨 번호의 출현 횟수를 저장하는 공간으로 사용해서 프로그램을 작서해 보자.
freqency = [0] * 46
File.foreach("로또당첨번호.txt") do |str|
nums = str.split
for i in 0..5
no = nums[i].to_i
freqency[no] += 1
end
end
p freqency
파일 편집기를 열어 위의 코드를 작성한 후 로또당첨번호.txt 파일이 있는 폴더와 동일한 곳에 lotto_freqency_by_array.rb 이름의 파일로 저장해 보자. 나는 D:/blog/ruby/lotto 폴더 아래에 저장하였다.
파일 이름은 여러분이 원하는 대로 다르게 해도 되지만 파일 확장자는 .rb 로 하는 것이 좋다.
그리고 해당 파일이 있는 폴더에서 cmd 창을 열고 아래 그림처럼 ruby 명령을 통해 방금 파일로 저장한 프로그램을 실행시킬 수 있다.
이렇게 파일로 코드를 저장해 놓으면 필요할 때 몇 번이고 실행할 수 있게 된다. irb 에서는 간단한 연습 및 테스트를 하고 계속 사용하거나 참조할 만한 프로그램 코드는 파일에 작성하면 된다.
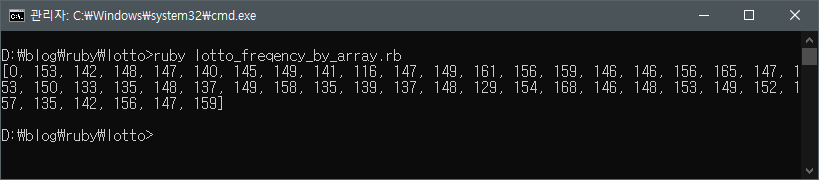
우선 여기선 화면 출력을 위해 puts 메서드가 아니라 p 메서드를 사용했다. puts 메서드로 배열을 출력하게 되면 요소 하나 하나 마다 개행 문자를 붙여 출력하기 때문에 한 눈에 볼 수 없게 된다. 그래서 출력 대상 값의 형태를 그대로 화면에 보여주는 p 메서드를 사용하였다. irb 를 열어 문자열, 숫자, 배열 등을 각각 p 와 puts 을 사용해 테스트 해보자.
다시 돌아와 위의 실행 결과를 보면 과연 어떤 숫자가 가장 많이 1등 당첨 번호에 출현했는지 한 눈에 알아 보겠는가?
아마 출현 빈도 Top 10을 찾기는 더 어려울 것이다. (첫 번째 0 은 실제 사용하지 않은 배열 요소이기 때문에 무시하면 된다.)
그렇다면 이제 필요한 것은 정렬이다. 또한 배열 요소의 값을 그냥 그대로 정렬해 버리면 어떤 숫자의 출현 횟수를 말하는 지 알 수 없게 되므로 먼저 숫자와 출현 횟수를 서로 짝을 지어줘야 한다.
아래 코드를 보면 배열(객체)의 zip 메서드가 두 배열에서 같은 인덱스의 요소들을 서로 짝을 지어 각 쌍을 담은 배열들을 또 다른 배열에 담아 돌려주는 것을 볼 수 있다.
우리가 잠바 등 지퍼 달린 옷을 입을 때 지퍼를 올리면 지퍼 양 쪽이 서로 맞물리면서 다물어지는데 이것을 떠올려 보면 zip(zipper) 메서드가 하는 일이 쉽게 이해가 될 것이다.
>> arr1 = ["A", "B", "C"]
=> ["A", "B", "C"]
>> arr2 = [1,2,3]
=> [1, 2, 3]
>> arr2.zip(arr1)
=> [[1, "A"], [2, "B"], [3, "C"]]이제 진짜 정렬을 알아볼 차례인데 다음 그림처럼 irb 를 실행해서 sort 와 sort_by 메서드를 직접 테스트해 보자.
>> [3, 2, 5, 1, 4].sort
=> [1, 2, 3, 4, 5]
>> ["B", "A", "c", "a", "C"].sort
=> ["A", "B", "C", "a", "c"]
>> ["Aaa", "Ab", "Aa", "Aaaa"].sort
=> ["Aa", "Aaa", "Aaaa", "Ab"]
>> ["Aaa", "Ab", "Aa", "Aaaa"].sort_by { |e| e.length }
=> ["Ab", "Aa", "Aaa", "Aaaa"]sort 메서드는 기본적으로 오름 차순 정렬이므로 가장 작은 값이 젤 앞에 위치하게 된다.
알파벳의 경우 당연히 알파벳 순서로 정렬이 되는데 대소문자 끼리의 비교에서는 대문자가 소문자 보다 앞에 오게 된다.
이것은 아래 보이는 ASCII 코드표를 보면 알 수 있는데, irb 에서도 "A".ord 와 "a".ord 를 각각 실행해 보면 실제 65 와 97 이 나오는 것을 볼 수 있다.
여러 개의 문자가 포함된 문자열 끼리의 비교는 첫 글자부터 서로 비교를 시작하는데 문자열의 길이가 더 짧더라도 어느 위치의 문자가 비교 대상 문자열의 같은 위치의 문자 보다 더 크다면 정렬에서 더 큰 문자열로 평가된다.
그래서 "Ab" 와 "Aaaa" 을 비교하여 정렬 했을 때 "Ab" 가 더 뒤에 나오게 되는 것이다. 당연히 "Aa" 와 "Aaa" 의 비교는 두 번째 문자까지는 같은데 "Aa" 의 길이가 "Aaa" 보다 더 짧기 때문에 정렬 결과 "Aa" 가 "Aaa" 보다 앞에 나온다.

그렇다면 문자열들을 정렬할 때 단순히 문자열의 길이만으로 크기를 비교하여 정렬을 하고 싶을 때는 어떻게 할까? sort_by 메서드를 사용하면 된다. sort_by 메서드에 블록( { ... } 또는 do...end )을 전달하여 실행하면 배열의 요소들을 순서대로 블록 파라미터(e)에 전달하여 블록의 내용( e.length )을 실행하고 그 결과 값들을 가지고 실제 비교하여 정렬하게 된다.
그래서 위의 sort_by 예제를 보면 "Aaaa" 가 길이가 가장 길어서 정렬 결과 젤 끝에 오게 된 것이다.
이제 아래처럼 작성해서 프로그램을 마무리해 보자.
freqency = [0] * 46
File.foreach("로또당첨번호.txt") do |str|
nums = str.split
for i in 0..5
no = nums[i].to_i
freqency[no] += 1
end
end
numbers = (0..45).to_a
num_freq_pairs = numbers.zip(freqency)
num_freq_pairs.shift # 첫 번째 요소 [0, 0] 을 버린다
pp num_freq_pairs.sort_by { |e| -e[1] }테스트를 위해 먼저 앞의 코드를 D:/blog/ruby/lotto 폴더 아래 lotto_freqency_by_array_sort.rb 파일로 저장하자.
그리고 같은 폴더의 위치에서 cmd 창을 열어 lotto_freqency_by_array_sort.rb를 실행해 보자.

실행 결과를 보면 숫자 34의 출현 횟수가 168 번으로 가장 큰 것을 알 수 있는데 당연히 결과는 '로또당첨번호.txt' 의 내용에 따라 달라질 수 있다.
범위를 표현하는 Range를 이전 글에서 for 반복문을 다룰 때 잠깐 얘기했었는데 여기서는 로또 번호(1 ~ 45)가 담긴 배열을 쉽게 만들기 위해 Range의 to_a(to array) 메서드를 사용했다. 1..45 가 아니라 0..45 인 것에 주의하자. 그래야 지퍼가 제대로 올라간다.^^
pp 메서드는 데이터를 많이 담고 있는 복잡한 배열이나 해시(다음 글에서 바로 알아보자.)등을 사람이 알아보기 쉽게 예쁘게 출력(pretty print)해 준다.
배열의 shift 메서드는 이름 그대로 배열 안의 요소들을 왼쪽으로 한 칸씩 이동시킨다고 생각하면 된다. 즉 첫 번째 요소를 결과 값으로 주고 그 값은 배열에서 빠지게 된다. 위의 코드에서 첫 번째 요소는 출현 횟수를 집계할 때 단지 배열의 인덱스와 로또 번호를 일치시키기 위해 필요했던 것인데 최종 결과에선 필요가 없으므로 빼버렸다.
알다시피 여기서 변수 e 는 번호와 출현 횟수 쌍이 담긴 배열( 예: [1, 153] )을 받게 되는데 출현 횟수를 기준으로 내림 차순 정렬을 해야 하므로 -e[1] 이렇게 출현 횟수 값 앞에 마이너스를 붙였다.
다음에는 이러한 상황에서 사용하기 더 적합한 해시(Hash)에 대해 알아보고 해시를 사용하여 프로그램을 수정해 보자.
See you again~~