이번 글에서는 먼저 문자열에서 특정 문자열을 찾을 때 사용하는 메서드 몇 가지를 살펴보자.
먼저 include? 메서드는 대상 문자열 안에 특정 문자열이 포함되어 있는지를 알려주고, start_with? 메서드는 대상 문자열이 특정 문자열로 시작하는지를 알려주며, end_with? 메서드는 대상 문자열이 특정 문자열로 끝나는지를 알려준다.

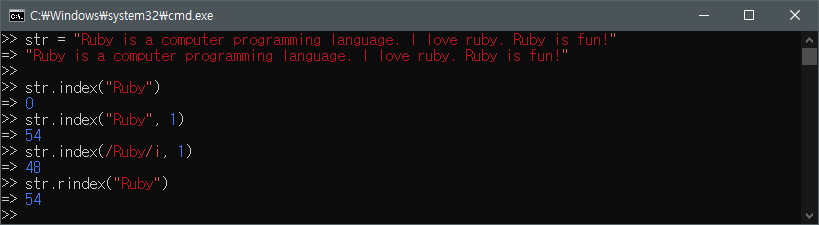
다음으로, index 메서드는 대상 문자열에서 특정 문자열을 찾았을 경우 시작 인덱스 값을 돌려주고, 찾지 못하면 nil을 돌려준다.
index 메서드는 두 번째 인수로 대상 문자열의 어디서부터 찾을지를 지정할 수 있는데, 그래서 아래 그림에서 보이는 것처럼 str.index("Ruby") 은 결과로 0을 돌려주지만, str.index("Ruby", 1) 은 str 문자열의 "Ruby is fun!" 에서 "Ruby"를 찾게 되어 54를 반환했다.
그리고 index 메서드는 정규 표현식을 사용하여 찾을 수도 있는데, str.index(/Ruby/i, 1) 은 대소문자 구분없이 "Ruby"를 대상 문자열의 인덱스 1부터 찾기 때문에 "I love ruby." 에서 처음으로 찾아 48을 돌려준다.
마지막으로 rindex 메서드는 대상 문자열의 끝에서부터 역(reverse)으로 찾는데, 그래서 str.rindex("Ruby") 는 "Ruby is fun!" 에서 "Ruby"를 찾아 54를 돌려준다.
그리고 String 클래스에는 index 메서드와 유사하게 대상 문자열에서 특정 패턴의 문자열이 처음 시작되는 위치를 알려주는 패턴 매칭 연산자 =~ 도 있다.
다만, index 메서드와 달리 연산자 메서드 =~ 는 인수로 정규 표현식만 가능하다.
아래 그림을 보면 변수 str이 참조하는 문자열에서 특정 패턴의 문자열을 찾기 위해 =~ 을 사용하였고 결과로 해당 패턴의 문자열이 시작되는 위치 10을 돌려 받았다.
루비에서는 정규 표현식을 통해 문자열에서 특정 패턴을 검색하게 되면 그 결과를 전역변수에 저장해서 참조할 수 있도록 해준다.
매칭되는 전체 문자열은 $& 을 통해 참조할 수 있고, 첫 번째 capturing group에 해당하는 부분은 $1 으로, 두 번째는 $2 로 참조할 수 있다.
그리고 연산자 메서드 !~ 는 매칭되는 곳을 찾지 못하면 true를 반환하고, 찾게 되면 false를 반환한다.
두 값이 서로 같은지 비교하는 == 와 같지 않은지 비교하는 != 를 생각하면, !~ 연산자가 왜 그런 모양인지 이해가 될 것이다.

그리고 String 클래스에는 대상 문자열에서 특정 패턴의 문자열을 검색하는 것에 특화된 match 메서드와 scan 메서드가 있다.
match 메서드는 대상 문자열에서 인수로 받은 정규 표현식과 패턴이 일치하는 부분을 찾아 MatchData 객체로 결과를 돌려주는데 만약 찾지 못하면 nil을 반환한다.
match 메서드가 반환한 MatchData 객체에는 실제 매칭되는 문자열 정보를 담고 있는데, 배열의 [] 메서드와 유사한 방법으로 참조할 수 있다.
아래 결과를 보면 md[0]은 정규 표현식과 매칭되는 전체 문자열을 돌려주고 md[1]은 정규 표현식 내 첫 번째 capturing group(괄호로 둘러싸인 서브 정규 표현식)에 해당하는 부분을 돌려준다.
그리고, to_a 메서드를 사용하면 매칭되는 전체 문자열과 capturing group에 해당하는 문자열을 배열로 받을 수 있다.

match 메서드는 대상 문자열에서 처음으로 패턴이 일치하는 부분만을 찾는 반면 scan 메서드는 대상 문자열의 끝까지 패턴이 일치하는 부분을 계속해서 찾는다.
아래 예제를 보면 대상 문자열 "Ruby is easy!. ruby is fun!" 에 대해 동일한 정규 표현식 /ruby is .+?\b/i 을 주고 match 메서드와 scan 메서드를 호출하였는데, match 메서드는 처음 매칭되는 "Ruby is easy"에서 검색을 종료했지만, scan 메서드는 문자열의 끝까지 검색을 이어나가 ["Ruby is easy", "ruby is fun"] 을 결과로 반환하였다.
scan 메서드는 정규 표현식에 capturing group 이 없으며 매칭되는 모든 문자열을 찾아 배열로 돌려주고, 만약 정규 표현식에 capturing group이 있으면 capturing group에 해당하는 문자열들을 배열로 감싸 2차원 배열을 결과로 돌려준다.
아래 그림의 마지막 예제를 보면 정규 표현식 안에 capturing group이 두 개 있는데, 결과 배열에 두 capturing group에 해당하는 문자열들이 모두 포함되어 있는 걸 볼 수 있다.

다음으로 문자열에서 특정 문자열을 찾아 원하는 문자열로 바꾸고 싶을 때 사용하는 sub 메서드 와 gsub 메서드를 살펴보자.
sub 메서드의 'sub'는 'substitute(대체물, 대신하다)'의 약자이고 gsub 메서드의 'g'는 'global'을 의미한다.
아래 그림을 보면 sub 메서드는 인수로 준 문자열 또는 정규 표현식과 첫 번째로 일치하거나 매칭되는 문자열만 바꾸지만, gsub 메서드는 대상 문자열의 끝까지 찾아 변경한다.
그리고 블록을 전달하여 매칭되는 문자열을 대치할 문자열을 동적으로 생성해 낼 수도 있다.
그래서 str.gsub(/Ruby/i, "Java") 코드는 뒤의 소문자 'ruby'까지도 모두 'Java'로 일괄 변경하지만, 그다음 코드는 블록을 통해 매칭되는 문자열의 첫 글자를 검사하여 'ruby'는 'java'로 대치할 수 있었다.
sub와 gsub 메서드의 두 번째 인수로 해시를 주면, 매칭되는 문자열을 키로 해시를 검색해서 찾은 값(의 문자열 표현)으로 대치한다.

match, scan, gsub 메서드를 실제 프로그램에서 사용하는 예를 보고 싶다면 '단어 검색기 만들기' 글을 참고하면 좋을 것 같다.
다음 그림은 문자열의 각 문자들을 요소로 하는 배열을 반환해 주는 chars 메서드와 각 문자들을 블록에 넘겨 반복 처리를 해주는 each_char 메서드의 예제를 보여준다.
그리고 배열과 동일하게 문자열에도 순서를 반대로 바꿔주는 reverse 메서드가 있다. 당연히 reverse 메서드를 연달아 두 번 호출하면 원래의 순서와 동일한 문자열을 돌려 받게 된다.

끝으로 루비에서 여러 줄의 문자열을 편하게 작성할 수 있는 Here Document 라는 기능을 설명하면서 이 글을 마칠까한다.
아래 그림을 보면 Hear Document를 사용하는 간단한 방법 몇 가지를 볼 수 있다.
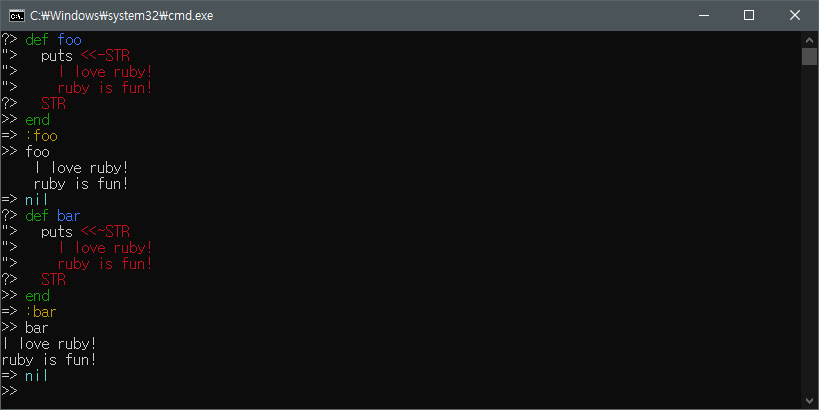
Hear Document 작성을 위해서는 문자열의 종료를 나타내는 구분자가 필요한데, 아래 예에서는 'EOS'를 구분자로 정의하였다.
첫 번째 '<<구분자 ... 구분자' 형식은 마지막 종료를 의미하는 구분자 앞뒤에 공백이 허용되지 않고, 두 번째 '<<-구분자 ... 구분자' 형식과 세 번째 '<<~구분자 ... 구분자' 형식에서는 마지막 종료 구분자 앞에 공백이 허용된다.
그리고 세 번째 형식을 사용하면 작성하는 내용을 쉽게 들여 쓰기할 수 있는데, 첫 번째 줄의 시작 위치가 기준이 된다.

아래 그림을 보면 foo 메서드에서 코드를 보기 좋게 작성하기 위해 Here Document 의 내용을 들여 쓰기 한것 뿐인데, 실제 화면에는 원치않는 공백이 출력된 것을 볼 수 있다.
이럴 때는 Hear Document 작성 시 bar 메서드의 코드처럼 '<<~구분자 ... 구분자' 형식을 사용하면 된다.
그리고 당연히, 작성한 내용 그대로를 원한다면 '<<-구분자 ... 구분자' 형식으로 Hear Document 를 작성하면 된다.
Hear Document로 작성한 문자열도 변수에 할당할 수 있으며, 당연히 인터폴레이션(#{..})도 사용할 수 있다.

지금까지 얘기한 것 말고도 문자열과 관련된 기능들이 더 많이 있고 조금 더 깊이 다뤄야 할 내용도 있겠지만, 그것에 관해서는 앞으로 글을 작성하면서 필요할 때마다 설명을 하도록 하겠다.
See you again~~