오늘은 지난 글에 이어 MyEnumerable 모듈에 몇 가지 메서드를 더 만들어 보겠다.
우선 sort_by 부터 시작해 보자.
sort_by 메서드는 실행 시 블록을 받아 블록의 결괏값을 기준으로 정렬을 해주는 메서드이다.
다음 그림을 보면 sort 메서드와 sort_by 메서드의 차이를 알 수 있다.
sort 메서드도 블록을 받아 정렬 기준을 변경할 수는 있지만 블록의 결괏값은 0, 양수, 음수 중 하나여야 한다.
즉 블록에 전달된 두 요소를 비교한 결괏값이 블록의 결괏값이라고 간주하다.
그에 반해 sort_by 메서드는 블록의 결괏값 자체를 가지고 비교를 하여 원래 요소들의 정렬 순서를 결정한다.
그래서 숫자 배열의 경우 내림차순 정렬을 위해 sort 메서드에 블록을 전달하여 두 요소의 순서를 바꿔서 비교해도 되지만, 아래 예처럼 sort_by 메서드에 전달한 블록에서 요소 값의 부호를 반전시켜도 된다.
그리고 문자열의 크기를 서로 비교할 경우에는 첫 번째 글자부터 순서대로 비교를 해나가는데, 알파벳 문자의 경우 ASCII 코드 체계에 따라 순서상 뒤에 나오는 알파벳이 앞의 알파벳 보다 크고 같은 알파벳의 경우 소문자가 대문자보다 크다.
아래 sort 메서드는 알파벳 문자열들을 ASCII 코드 체계에 따라 오름차순으로 정렬했지만, sort_by 메서드를 사용하여 ASCII 코드 체계와 상관없이 문자열의 길이를 기준으로 비교를 해보았다.

이제 sort_by 메서드를 MyEnumerable 모듈에 작성해 넣은 아래 코드를 보자.
이미 만들어 놨던 sort 메서드와 거의 비슷한 형태이고 다만 while 반복문 안에서 result 배열 안의 요소들과 비교를 할때 sort 메서드와 달리 요소 자체를 비교하지 않고 블록에 요소를 전달하여 실행한 결괏값을 비교하고 있다.
result 배열 안의 요소들에 대해 반복적으로 블록을 실행해야 하기 때문에 요소의 수가 많을 경우 성능면에서는 좋지 않기 때문에 실전에서는 성능 개선이 필요할 수도 있다.
module MyEnumerable
...생략
def sort
result = []
reduce(result) do |a, b|
i = 0
while i < result.size
if block_given?
break if yield(b, result[i]) <= 0
else
break if b <= result[i]
end
i += 1
end
result.insert(i, b)
end
result
end
def sort_by
result = []
reduce(result) do |a, b|
i = 0
while i < result.size
break if yield(b) <= yield(result[i])
i += 1
end
result.insert(i, b)
end
result
end
endsort_by 메서드의 테스트를 위해 D:/blog/ruby/enumerable 폴더에 아래 코드를 test_sort_by.rb 파일에 작성하여 저장한 후 해당 폴더 위치에서 cmd 창을 열어 test_sort_by.rb 파일을 실행해 보자.
require './my_enumerable'
class MyArray
include MyEnumerable
def each
yield("b")
yield("AAA")
yield("a")
yield("BB")
end
end
my_arr = MyArray.new
p my_arr.sort
p my_arr.sort_by { |e| e.length }원하는대로 문자열의 길이를 기준으로 정렬이 잘 되는 것을 확인할 수 있다.

이번에는 take 메서드와 take_while 메서드를 만들어 보자. take 메서드는 인수로 받은 숫자 만큼의 요소를 새 배열에 담아 돌려 주고 take_while 은 블록의 결괏값이 참으로 평가되는 동안의 요소를 새 배열에 담아 돌려준다.
아래 그림을 보면 take 메서드와 take_while 메서드가 어떻게 동작하는지 알 수 있다.
take_while 메서드의 예를 보면 대상 배열에 홀수가 1, 3, 5 세 개가 있지만 5 이전에 2에서 블록의 결괏값이 거짓이 되어 더 이상 진행하지 않고 [1, 3] 배열을 반환하고 끝낸다.
이미 알고 있겠지만, select 메서드는 블록의 결괏값이 참이 되는 모든 요소를 새 배열에 담아 돌려준다.

아래 코드처럼 take 메서드와 take_while 메서드를 MyEnumerable 모듈에 추가해 보았다.
take 메서드는 인수로 음수를 줄 경우 예외를 던지도록 했고 each_with_index 메서드를 사용하여 인덱스 i가 파라미터 num보다 작을 동안만 result 배열에 요소를 담는다.
take_while 메서드는 each 메서드를 사용하여 take_while 메서드에 전달된 블록의 실행 결괏값이 참이 되는 동안만 result 배열에 요소를 담는다.
module MyEnumerable
...생략
def take(num)
raise ArgumentError.new("attempt to take negative size") if num < 0
result = []
each_with_index do |e, i|
break if i >= num
result << e
end
result
end
def take_while
result = []
each do |e|
break if !yield(e)
result << e
end
result
end
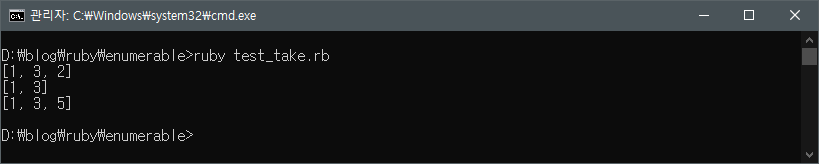
end기존과 동일한 폴더에 test_take.rb 파일을 아래 코드의 내용으로 작성하여 저장하고 같은 폴더 위치에서 cmd 창을 열어 test_take.rb 파일을 실행해 보자.
require './my_enumerable'
class MyArray
include MyEnumerable
def each
yield(1)
yield(3)
yield(2)
yield(5)
yield(4)
end
end
my_arr = MyArray.new
p [1, 3, 2, 5, 4].take(3)
p [1, 3, 2, 5, 4].take_while { |e| e.odd? }
p [1, 3, 2, 5, 4].select { |e| e.odd? }앞서 배열로 take 메서드와 take_while 메서드를 테스트했을 때와 똑같은 결과가 나오는 것을 볼 수 있다.
drop 및 drop_while 메서드는 각각 take 및 take_while 메서드와 반대로 동작하는 메서드이다. 아래 간단한 예를 보자.
drop 메서드에 인수로 3을 주면 앞에서부터 요소 3개를 제외하고 나머지 요소들을 새 배열에 담아 돌려준다.
drop_while 메서드는 블록의 결괏값이 참이 되는 동안의 요소들은 제외시키고 나머지 요소들을 새 배열에 담아 돌려준다. 그래서 홀수 5가 배열에 있지만 2에서 블록의 결괏값이 거짓이 되어 5는 결과 배열에 담기게 된다.
select 메서드를 사용하면 모든 홀수를 걸러내고 짝수만 담은 배열을 받을 수 있다.

아래처럼 drop 메서드와 drop_while 메서드를 간단히 작성해 보았다.
drop 메서드는 each_with_index 메서드를 사용하여 인덱스 i가 num보다 크거나 같은 요소들만 result 배열에 담는다. 인덱스는 0부터 시작이고 num은 양의 정수이기 때문에 num보다 작은 인덱스의 요소들만 제외하면 되는 것이다.
물론 인수 값의 검사를 간단히 하였기 때문에 0.9 나 1.1 같은 실수도 인수로 줄 수 있지만 여기서는 핵심 로직에만 집중하면 좋을 것 같다.
참고로, Java나 C#과 같은 언어들은 파라미터에 타입을 지정해야 하고 프로그램을 실행하기 전에 컴파일 단계를 거쳐야 하지만, 컴파일 시에 인수로 전달될 값의 타입을 미리 검사해 주기 때문에 실행 시 발생할 수 있는 오류를 줄여준다.
그에 반해, 루비나 파이썬과 같은 언어들은 파라미터에 타입을 지정할 필요가 없고 실행을 위해 컴파일 작업을 개발자가 따로 신경쓸 필요가 없지만, 인수로 전달될 값의 타입이 런타임에 결정되므로 (필요하다면) 타입을 검사하기 위한 코드를 추가적으로 작성해야 한다.
drop_while 메서드는 블록의 결괏값이 처음 거짓이 되면 더 이상 블록을 실행하지 않고 요소들을 새 배열에 담아야 하는데, 그래서 블록의 결괏값이 거짓일 때 found 변수에 true를 할당하여 다음 요소들부터는 블록을 실행하지 않도록 했다.
블록 안에서 next를 호출하면 next 이후의 코드를 건너뛰고 그 다음 반복의 블록 실행으로 넘어간다.
module MyEnumerable
...생략
def drop(num)
raise ArgumentError.new("attempt to drop negative size") if num < 0
result = []
each_with_index do |e, i|
result << e if i >= num
end
result
end
def drop_while
result = []
found = false
each do |e|
next if !found && yield(e)
found = true
result << e
end
result
end
end역시 동일한 폴더에 test_drop.rb 파일을 아래 코드의 내용으로 작성하여 저장하고 같은 폴더 위치에서 cmd 창을 열어 test_drop.rb 파일을 실행해 보자.
require './my_enumerable'
class MyArray
include MyEnumerable
def each
yield(1)
yield(3)
yield(2)
yield(5)
yield(4)
end
end
my_arr = MyArray.new
p [1, 3, 2, 5, 4].drop(3)
p [1, 3, 2, 5, 4].drop_while { |e| e.odd? }
p [1, 3, 2, 5, 4].select { |e| e.even? }실행 결과를 보면 원하는대로 결과가 잘 나오는 것을 볼 수 있다.

다음 글에서는 MyEnumerable 모듈에 min, max, sum 메서드를 만들어 보겠다.
See you again~~